Alumni

Rachna Gupta
Bio
Rachna Gupta is a rising junior at the Illinois Mathematics and Science Academy (IMSA). Rachna is passionate about math, computer science, and chemistry and constantly challenges herself. She is an avid quizbowl player and is on her school's varsity team. In addition, Rachna enjoys working with kids and leads as well as teaches STEM innovation camps for elementary and middle school students. She is very involved in her community and loves to volunteer at her local hospital. Rachna is very passionate about research and has presented at conferences, most recently NCSSS in June 2019. Currently, she is researching at Feinberg School of Medicine. In her free time, she reads, plays the flute, and listens to music. Rachna is looking forward to furthering her knowledge of computer science, math, and science at the Wolfram Summer Research Program.
Project: Classifying Fiction and Non-Fiction Works Using Machine Learning
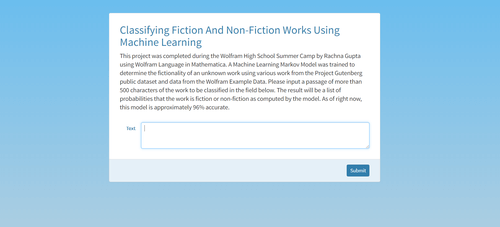
Goal
The objective of this project is to create a program that can determine whether an unknown text is a work of fiction or nonfiction using machine learning. This project utilizes various datasets of speeches, ebooks, poems and scientific papers and more texts from Project Gutenberg and the Wolfram ExampleData fuction to train and test a Markov chain machine-learning model. The final product is a microsite that returns a probability of fictionality based on input from the user.
Summary of Results
In order to achieve my objective, I first obtained a dataset of 3036 works of fiction and nonfiction from Project Gutenberg and added the 50 works from the ExampleData function in Mathematica. I manually sorted all the data into fiction and nonfiction and split them into sections of 5000 characters for training various machine-learning models. I determined that a Markov chain model trained on a selection of 325 works from my dataset yielded the highest accuracy of 96%. I deployed this model as a microsite that takes a work inputted from the user and returns the probability that the work is fiction or non-fiction.
Future Work
In the future, I will explore the possibility of using more data from the Wolfram Data Repository to train the model and increase the accuracy. I will also attempt to create a scale from fiction to non-fiction and map different works onto that scale to define the genres within fiction such as historical fiction, fantasy, and realistic fiction.