Alumni

William Goodall
Bio
William Goodall has had a lifelong interest in technology, and will attend Georgia Tech to study computer science this fall. He has developed several applications in his free time, including an efficient heuristic solver for Shikaku puzzles, a cryptographically-authenticated microblogging service, and a dynamic cookbook app based on graph theory. William competes regularly in several hackathons and coding competitions around Montclair, New Jersey, where he lives. When he’s not writing code, you can find him cooking, or working on photography projects.
Project: Fitting the World: Determining Physical Scale from Satellite Images
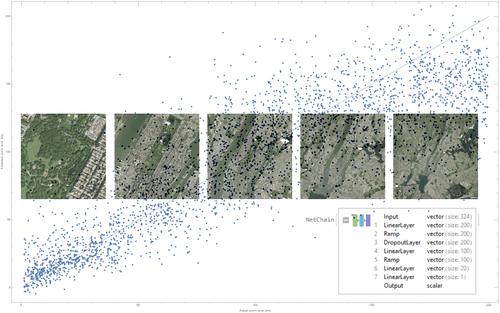
Goal
We create an algorithm that can deduce physical scale from a satellite image, the correspondence between distance in pixels and distance in kilometers. This is a very challenging problem because of the nature of the world's terrain; at different zoom levels, it's highly self-similar. We need a method to extract useful information from these images while also ignoring the parts that are self-similar. While we explored several approaches to this problem, the most successful solution used feature extraction to convert each image to a small vector then trained a small feed-forward neural network to predict zoom from each set of features. Although the self-similarity of each image makes more traditional CV approaches very difficult, a neural network can learn the right features to approximate zoom well.
Summary of Results
We created several models that all do a fantastic job at modeling a few very specific things. The model trained on the continental United States was flexible—you could pass it an image from mostly anywhere in the country, and it would classify its position to a fairly good degree of accuracy. The model trained on Massachusetts was inflexible but far more accurate. Given a limited set of data from DigitalGlobe, within a small area, it could predict zoom levels with great accuracy. However, move outside of that area and it would break. For both networks, using a different imagery provider breaks the prediction. Taking a look at the DigitalGlobe and Wolfram satellite data, we can begin to see why; the color grading of the two images is completely different. This would explain the loss in precision if the networks were really trained on the fine-grained and unstable detail of the images rather than the human-readable patterns. In terms of the ideal solution to this problem, a function that takes any satellite image and returns its physical scale, we fell short. With the limited (two-week) scale of this project, gathering enough data and training a network general enough to successfully predict the zoom of any satellite image proved to be very difficult. However, what we did create—a neural network that can successfully classify images from one provider to a fairly high accuracy—is a good start.
Future Work
One of the larger problems with this research was gathering data. In future attempts, it would be better to gather a much larger dataset (somewhere around 50,000 images) from several different satellite providers. To stop the network from overfitting on the fine-grained style of the images, we would need to find satellite providers whose data are significantly different. One other option is to improve the model's feature extraction layer. Right now, the FeatureExtraction function uses the first few layers of the Wolfram ImageIdentify classifier, coupled to an autoencoder. By making a feature extractor that operates only on our data, we might be able to get better results.