Alumni

Bio
Mengyi Shan is a first-year student from Harvey Mudd College in California, the United States. She stayed in Beijing, China, before college. With a great math background and enthusiasm for math’s application, she plans to double major in mathematics and computer science. For now, her research interests fall mainly within computational creativity, including math’s and computer science’s applications in music, picture, language and other kinds of art. Besides being a programmer, she is also an amateur singer, a ballroom dancer and a fairy tale writer. As an enthusiast of the Wolfram Language since high school, she believes the Wolfram Summer School will be a wonderful start to her scientific research.
Computational Essay
Project: Punctuation Restoration with Recurrent Neural Networks
Goal
Punctuation restoration is an indispensable step in some natural language processing processes. This project aims to build an automatic “punctuation adding” tool for plain English text with no punctuation. Several models built from various neural networks are examined based on F1 score.
Main Results in Detail
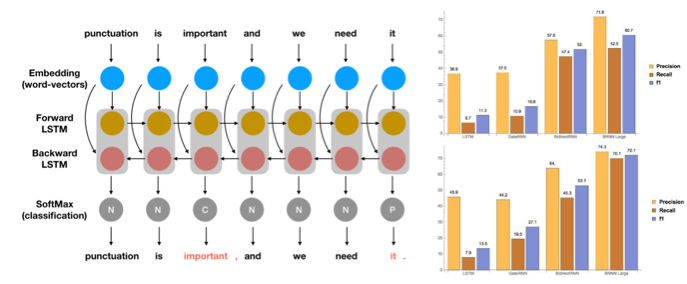
Ten neural networks are trained based on a small dataset with different layers. Only using LongShortTermMemoryLayer gives an F1 score of 13% and 11% for periods and commas. Introducing DropoutLayer, PoolingLayer, ElementwiseLayer, BasicRecurrentLayer and GateRecurrentLayer produces an F1 score between 10% and 30%, showing no significant improvement. The introduction of a bidirectional operator (combining two recurrent layers) to the previous tests improves the scores to 53% and 47% and to 72% and 60%, respectively, when training on a larger dataset of 10 million words.
Future Work
Planned future work focuses on improving accuracy to a level suitable for usage in industry. Since the LTSM network and bidirectional operator show great potential, two possible directions are increasing the number of layers and neurons and training with a larger and cleaner dataset.