Alumni

Matias Shundi
Bio
Matias Shundi is a rising senior at Chapel Hill High School in North Carolina. As a highly advanced and hard-working student in math, physics, and computer science, Matias has been dual-enrolled and is taking many classes at the University of North Carolina at Chapel Hill, having currently worked his way up to graduate-level courses. He is the president of his school's math club, and participates in many math competitions, where he has consistently been a top performer at the state and national level. His hobbies include playing chess—where he is a one-time state champion—and scrabble—where he has finished in 2nd place twice and 3rd place once in the North American School Scrabble Championship. He enjoys playing sports, with his favorites being basketball and tennis. He is very passionate about computer science and math, and hopes to continue exploring these fields.
Project: Creating Phylogenetic Graphs of Programming Languages with Machine Learning
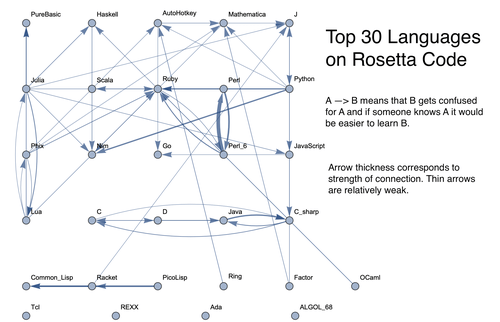
Goal
Phylogenetic trees are meant to show evolutionary relationships between species, and versions exist that show historical developments of programming languages. However, these relationships aren't always the most indicative in terms of how similar syntaxes are, and they are limited as graphs. This project's goal was to develop graphs that show relationships between computer languages based off of syntactical factors instead of historical factors. The value in such a graph would be not only showing relationships but providing insight on what languages might be most natural to learn for someone who knows a given language, and it would show what some of the easiest orders to learn languages would be. It also would give more insight into the potential of machine learning to determine such relationships.
Summary of Results
The result was functions that would generate graphs for a list of languages, showing all connections having strength above a specified threshold and having the thickness of edges correspond to their strengths. Relationships between programming languages were determined by how often a machine-learning classifier would confuse languages for each other. On the graph, an arrow from A to B means that B gets confused for A, and someone who knows language A would therefore find it easier to learn language B. Few pairs of languages exist that have strong connections going both ways. All data used came from Rosetta Code, which provides tasks written in different program languages. Individual programs were scraped off of the website by using Mathematica to parse the HTML. This data was saved once extracted, as there were close to 1,000 languages and almost 1,000 unique programming tasks. A dataset would be made with programs of all languages that were going to be in the graph. The benefit of using Rosetta Code was that most of the data was of programs doing the same task but coded in different languages. A machine-learning classifier would train and test on parts of the data, and confusion between languages would indicate a relationship, with higher amounts of confusion corresponding to a stronger relationship. The two main functions created were one that creates a manipulable graph and one that creates a static graph. Both take in either an integer representing the top n languages or a string of space-separated languages. This determines what languages to include in the graph. The manipulable graph allows the user to change the threshold of the edge strength and the graph layout, while the static graph requires that these two are passed as parameters beforehand.
Future Work
The results from the generated graphs were reasonable and promising, suggesting that similar methods could be used for larger datasets and fields. While the historical influences of programming languages on each other are relatively well known, this could potentially help in finding relationships in writing, music and even art, both in the past and in the present. Machine learning is capable of handling larger amounts of data than what is available with computer languages, and it would likely scale well for these broader fields.