Alumni

Dev Chheda
Bio
Dev is a rising junior at Ardrey Kell High School and at the North Carolina School of Science and Mathematics Online Program in North Carolina. Dev has been passionate about science, mathematics, and technology for many years, and actively pursues these subjects in his free time. Dev also loves teaching, and coaches local middle school math clubs, leads his high school math club, volunteers to tutor children at the public library, and has coached the North Carolina state MATHCOUNTS team. Dev has competed and won in numerous contests, including MATHCOUNTS, AMC/AIME, USAJMO, USACO, ARML, and ISEF. Dev is an entrepreneur in the mobile app industry, having published apps on the App Store and the Google Play store. Dev is also enthusiastic about music, dance, and theatre—he has performed on stage for more than 8 years, and has recently performed at the Children’s Theatre of Charlotte in Broadway-esque musicals.
Project: Mood Detection in Human Speech
Goal
We aim to design a system that is capable of detecting mood in human speech. Specifically, the system can be trained on a single user's voice given samples of emotional speech labeled as being angry, happy or sad. The system should then be able to classify future audio clips of their speech as belonging to one of these three moods. We first preprocess audio clips to reduce noise and allow for easier analysis of the audio data. Then we extract and analyze features of the training data that are used to build a classifier function in the Wolfram Language. The analyzed features include amplitude, fundamental frequency, word rate, formants and pausing time in the audio clips. After the classifier function is constructed, it is tested on more speech clips from the same speaker. The classifier attempts to correctly classify the clips into the three moods. We implement many different methods for the classifier function and compare their accuracies to find the optimal classifier.
Summary of Results
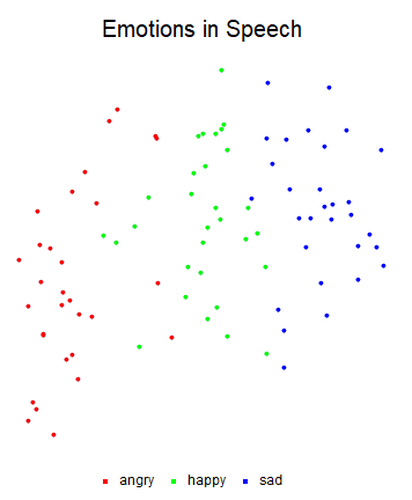
We recorded 10 clips in each mood to be used as training data and 10 different clips in each mood to be used as testing data. Many different classifiers were trained using the in-built methods for classifier functions in the Wolfram Language. We found that the classifiers with the best accuracies on the testing data were the LogisticRegression and NearestNeighbors classifiers at 77% accuracy and 73% accuracy, respectively. We then implemented an audio cleaning function, which boosted the accuracies of the LogisticRegression and NearestNeighbors classifiers to 87% accuracy and 80% accuracy, respectively. Through the use of feature space plots, we found that there are extreme differences between the angry and sad moods (such that they are never confused for each other), while the happy mood lies between angry and sad, leading to some confusion for the classifier. We then tested the classifier on clips of the same statement in different moods. That is, we recorded emotionally neutral statements in each of the moods to see if the content of the speech impacted the classifier function in any way. We found that the LogisticRegression classifier function was not impacted by the content of the speech, as it achieved 97% accuracy on the neutral statements testing data. Overall, the classifier was able to identify mood to a reasonable degree of accuracy, even when the same statements were spoken in different moods.
Future Work
In the future, we hope to improve the accuracy of the classifier by providing additional training data and to test it further with additional testing data. We also hope to expand the range of moods the the classifier handles, including moods such as fear, calmness and excitement. This, of course, would require the aforementioned additional data and perhaps more complex structures for the classifier function. In the future, we may also want to experiment with multiple speakers and determine whether classifiers for one speaker's moods can be used to determine those of another speaker.