Alumni

Nico Ademo
Bio
Nico is a rising junior at Heathwood Hall in South Carolina. His interests include algebraic geometry (specifically elliptic curves, modular forms, and monstrous moonshine), machine learning, and theoretical physics. During his free time, Nico enjoys playing jazz piano, reading Douglas Adams, and competing at the national level in Mock Trial. He also held, for the entirety of 2015, the official world record for iPad typing speed. He’s very proud of this fact, but would never admit it.
Project: Colorful Fraud: Utilizing Adversarial Examples to Expose Flaws in Neural Network Architectures
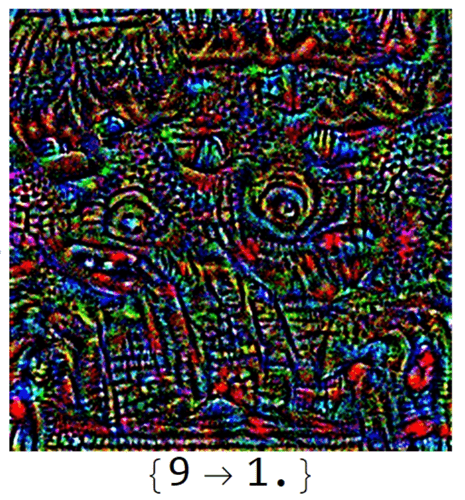
Goal
In a day and age where many consider deep learning an off-the-shelf solution to any and all classification/prediction problems, it's important that people examine whether their neural network models are vulnerable to targeted attacks. This project implements a framework for generating adversarial examples: input data crafted to cause the neural network to produce unexpected or targeted incorrect behavior. This is done using a known algorithm called FGSM as well as an original algorithm. Using these algorithms, we examine whether these adversarial examples are in fact edge cases or make up a majority of the neural network's classification space. We also construct two models for trying to minimize adversarial examples and evaluate their accuracy at detecting and overcoming adversarial images on the MNIST database.
Summary of Results
The results of this project can only be described as "bittersweet." It turns out that adversarial examples are not only directly instantiable but also make up a majority of the space of images classified by any given network as high probability. Neural networks are therefore incredibly vulnerable to targeted attacks of this manner, especially those dealing with low-dimensional vectors. Furthermore, there is no need to actually have access to the internals of the neural network, just the input and output. But there is hope! The transfer of adversarial examples between neural networks with arbitrary labeling can be exploited to filter out, theoretically, *all* adversarial examples, something that has never been accomplished before. In practical settings, it was also shown that just two neural networks, the original and a "filter network," are sufficient to filter out most, if not all, adversarial examples.
Future Work
The main facet of my project I'd like to continue to explore is a rigorous explanation for why adversarial examples transfer between networks with different classes. Informally, the phenomenon makes sense, but in terms of matrix mathematics and backpropagation, there is absolutely no easy explanation. I'd also like to scale up my defensive strategies to try to use them on full ImageIdentify networks rather than just MNIST. The concepts themselves should transfer, but implementation might have some key changes that are necessary to be aware of.